Stworzenie każdego większego systemu wymaga dobrego projektu. Głównym celem projektu jest uzyskanie optymalnej struktury bazy danych. Rodzaj stosowanej przy tym notacji jest najczęściej zdeterminowany używanymi narzędziami CASE. Teoretycznie rzecz biorąc należałoby rozpocząć od opisania struktury systemu – na przykład w postacie diagramów ERD. Ponieważ jednak ta część dokumentacji projektowej służy głównie programistom, jako podstawa implementacji, w praktyce często przechodzą oni od razu do projektowania struktur bazy danych, stosując bardziej naturalne dla siebie notacje. Dotyczy to zwłaszcza wszelkich metodologii „zwinnych” (agile). Projektując interfejs użytkownika lub implementując algorytmy, możemy natrafić na sytuację, w której niewielka zmiana struktury bazy danych bardzo ułatwia zadanie. Istnienie dodatkowego poziomu konceptualnego w postaci modelu obiektowego może utrudnić to zadanie i powodować komplikowanie implementacji poprzez tworzenie piętrowych złożeń i skomplikowanych funkcji składowanych. Dla przykładu, jeśli nie przewidzieliśmy w bazie pola zawierającego informację, czy pracownik jest nadal zatrudniony, można tą informację uzyskać na podstawie analizy historii zatrudnienia. Łatwiej jest jednak wprowadzić nowe pole w bazie danych, a jego uzupełnienie powierzyć odpowiednim triggerom. Analizując dostępne na rynku systemy produkowane przez duże firmy nieraz można spotkać rozwiązania, które z całą pewnością nie powstały z zastosowaniem zwinnych metodologii.
Z drugiej strony wykonanie analizy konceptualnej przed projektem bazy danych ma swoje zalety. Umieszczenie na diagramie bogatszych informacji pozwala na lepszą analizę kompletności projektu. W większych zespołach projektowych może też ułatwić komunikację.
Analiza obiektowa
W analizie obiektowej nie operujemy tak naprawdę obiektami, ale ich klasami. Dla przykładu na diagramie UML nie pojawia się obiekt odpowiadający konkretnemu pracownikowi, ale klasa obiektów typu pracownik. Każdy obiekt/klasa ma swoją nazwę i atrybuty. Klasy obiektów określają jedynie, jakie atrybuty ma obiekt danej klasy. Są to cechy niezmienne (inwarianty) – na przykład: każdy pracownik posiada jakieś nazwisko i identyfikator. Konkretny obiekt może mieć nazwisko „Kowalski” i identyfikator „1234”. Na diagramach umieszczamy jedynie nazwy atrybutów – a więc operujemy klasami, a nie konkretnymi obiektami.
Poniższy rysunek zawiera przykład takiej analizy wykonanej dla systemu płatności komórką przy użyciu programu StarUML:
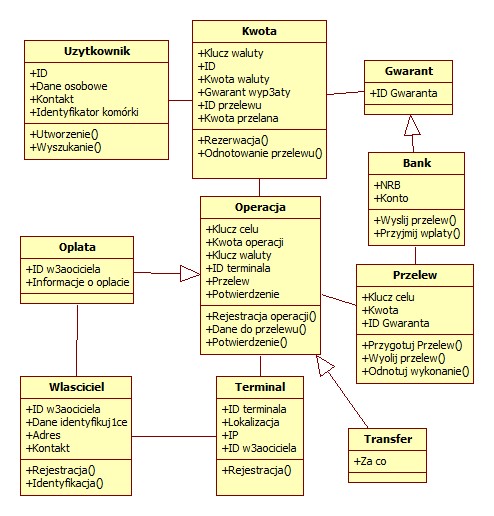
Zauważmy, że poza nazwą i atrybutami każda klasa może mieć zdefiniowane operacje (metody), jakie na obiektach tej klasy mogą być wykonywane.
Ponadto klasy są powiązane ze sobą. Związki te mogą być opcjonalne lub wymagane oraz wiązać jeden obiekt do wielu lub jeden do jednego. Znajduje to odzwierciedlenie w kształcie kresek, jakimi łączymy obiekty ze sobą.
W praktyce dostępnych jest wiele różnych notacji. Program StarUML operuje związami następującego rodzaju:
-
połączenie (association - kreski bez strzałek na powyższym diagramie),
-
agregacja (aggregation),
-
skład (composition),
-
uogólnienie (generalization - kreski ze strzałkami na powyższym diagramie),
-
zależność (dependency),
-
realizacja (realization)
Projektowanie struktur relacyjnych baz danych
Następnym krokiem po wykonaniu analizy strukturalnej (obiektowej) jest projekt bazy danych. Stosując narzędzia CASE schemat bazy danych uzyskuje się z notacji obiektowej automatycznie. Jest to zapewne jeden z powodów, dla których ważna umiejętność projektowania baz danych nie jest doceniana. Wraz z rozwojem metodologii zwinnych konieczny jest jednak powrót do tych fundamentalnych zasad projektowania. Poniżej przedstawiono te zasady, wprowadzając je w sposób nieformalny (bardziej ścisłe ujęcie można znaleźć w książce Ullmana podanej w spisie literatury).
Wprowadzenie
Przypuśćmy, że mamy dwa zbiory: tytułów książek i nazwisk. Na przykład:
A = { Mickiewicz, Sienkiewicz, ...}
T = { "Krzyżacy", "Potop", "Dziady", ...}
Iloczynem kartezjańskim AxT tych dwóch zbiorów nazywamy zbiór wszystkich par takich, że pierwszy element pary pochodzi ze zbioru A, a drugi ze zbioru T.
AxT = { (Mickiewicz, "Krzyżacy"),(Sienkiewicz,"Krzyżacy"),...}
Iloczyn kartezjański może być utworzony również z większej liczby zbiorów. Uogólnienie pojęcia 'pary' nazywa się w tym wypadku n-krotką. Iloczynem kartezjańskim zbiorów D1, D2, ... , Dn nazywamy zbiór wszystkich n-krotek (x1,x2, ... , xn) takich, że x1 jest elementem zbioru D1, x2 jest elementem zbioru D2, ... , xn jest elementem zbioru Dn.
Na pierwszy rzut widać ze sens mają jedynie pewne podzbiory krotek. Podzbiór iloczynu kartezjańskiego nazywa się relacją. Na przykład możemy ustalić relację JEST_AUTOREM, której elementami są krotki:
{(Sienkiewicz, "Krzyżacy"),(Mickiewicz, "Potop"), ...}
Z każdym elementem krotki związany jest określony rodzaj danych (w tym wypadku nazwiska, tytuły). Własność ta nazywamy atrybutem relacji. Dla każdego atrybutu określona jest nazwa (na przykład AUTOR, TYTUL) i dziedzina wartości, jakie może on przyjmować (zbiór nazwisk, zbiór tytułów). Schematem relacji nazywamy zbiór wszystkich atrybutów relacji. Schemat relacji przedstawia się zazwyczaj następująco:
JEST_AUTOREM ( AUTOR, TYTUŁ )
W bazach danych odpowiednikiem relacji jest tabela. Odpowiednikiem krotki jest rekord, a odpowiednikiem atrybutu jest pole rekordu. Schematowi relacji odpowiada struktura tabeli. Dalej będziemy używali dla opisu struktury tabeli/relacji uproszczonej notacji mającej swe źródło w systemie dBase. Każde pole jest opisywane przy użyciu identyfikatora (dużymi literami), typu danych (N – numeryczny, C – znakowy), wielkości i opisu (komentarza).
Rozważmy przykład relacyjnej bazy danych składającej się z jednej relacji o schemacie:
NUM_DOST N 2 Numer dostawcy
DOSTAWCA C 20 Nazwa dostawcy
ADRES C 25 Adres dostawcy
TOWAR C 11 Towar
CENA N 4 Cena
Przy dostępie do bazy danych mogą wystąpić następujące nieprawidłowości:
-
Redundancja - nazwa i adres dostawcy muszą być pamiętane w każdej krotce.
-
Anomalie przy aktualizacji - zmiana adresu w jednej krotce a przeoczenie zmiany w innej powoduje pojawienie się sprzecznych danych.
-
Anomalie przy wstawianiu - nie można wpisać adresu dostawcy, który nie dostarcza chwilowo żadnego towaru.
-
Anomalie przy usuwaniu - usunięcie wszystkich krotek dotyczących dostawcy powoduje utratę danych o jego nazwie i adresie.
W powyższym przykładzie łatwo zauważyć, że przy obsłudze niewłaściwie zaprojektowanej bazy danych, nawet tak niewielkiej, natknąć się można na wiele trudności. Problemy te można rozwiązać, organizując bazę danych nie w postaci jednej, lecz kilku relacji. Intuicyjnie można określić, że będą to relacje o schematach:
Relacja 1
NUM_DOST N 2 Numer dostawcy
DOSTAWCA C 20 Nazwa dostawcy
ADRES C 25 Adres dostawcy
Relacja 2
NUM_DOST N 2 Numer dostawcy
TOWAR C 11 Towar
CENA N 4 Cena
Przy takiej organizacji bazy danych wyeliminowane zostaną wszystkie niedogodności występujące w przypadku, gdy dane przechowywane były w jednej relacji. Intuicyjny projekt bazy danych może być wykonany dla niewielkiej ilości atrybutów i nieskomplikowanych zależnościach między nimi. W bardziej skomplikowanych przypadkach warto stworzyć projekt kierując się zasadami teorii.
Algebra relacji - podstawowe operacje
Suma
Suma relacji A i B jest zbiorem wszystkich krotek należących do relacji A lub należących do relacji B i tylko takich. Przykładem sumowania relacji jest wykonanie polecenia INSERT INTO A SELECT * FROM A; dla tabel o takiej samej strukturze.
Rożnica
Rożnica relacji A i B jest zbiorem tych krotek relacji A, które nie należna do relacji B i tylko takich. Dla tabel bazy danych, jeśli ID jest kluczem głównym w każdym z nich, różnicę otrzymamy w wyniku polecenia SELECT * FROM A WHERE ID NOT IN (SELECT ID FROM B);.
Iloczyn kartezjański
Iloczyn kartezjański relacji A o krotności k1 oraz B o krotności k2 jest zbiorem (k1+k2)-krotek, których pierwsze k1 składowych jest k1-krotką pochodzącą z A, a ostatnie k2 składowych jest k2-krotka pochodząca z B.
Rzut
Operacja rzutu polega na wybraniu kolumn tabeli reprezentującej relacje. Na przykład z tabeli KRAJE(NAZWA, STOLICA, KONTYNENT, POWIERZCHNIA) możemy dokonać rzutu na STOLICE_KRAJOW(NAZWA, STOLICA) poleceniem SELECT NAZWA STOLICA FROM KRAJE.
Jeśli przez R oznaczymy relacje (schemat relacji), a przez r schemat rzutu tej relacji, to mówimy o rzucie relacji R na r.
Selekcja
Operacja selekcji polega na wybraniu z relacji krotek (rekordów, wierszy) spełniających określony warunek. Jej odpowiednikiem jest polecenie.
SELECT * FROM A WHERE ... .
Złączenie
Złączenie relacji A i B względem określonych atrybutów złączeniowych (A1, ... , Ai) i (B1, ... ,Bj) oraz wyrażenia logicznego L jest relacja o następujących własnościach:
- schemat relacji jest suma schematów relacji A i B;
- łączone są te krotki relacji A i B, których wartości składowych. dla atrybutów połączeniowych spełniają wyrażenie L.
Złączenie naturalne
Jest to takie złączenie, że atrybuty złączeniowe dla obu relacji identyfikowane poprzez jednakowe nazwy, a warunek L jest koniunkcją warunków równości atrybutów o jednakowych nazwach. W przypadku z łączenia naturalnego do schematu relacji wynikowej atrybuty złączeniowe wchodzą jednokrotnie (przed złączeniem występowały dwukrotnie - w każdej z łączonych relacji).
Przykład
Dane są trzy zbiory:
Z (nazwy zwierząt), W (wysokość), K (kolor)
zawierające następujące elementy:
Z = { MYSZ , KOGUT , ŻYRAFA }
W = { 2 , 40 , 400 }
K = { BIAŁY , BRĄZOWY }
Iloczynem kartezjańskim tych zbiorów (Z x W x K) jest zbiór zawierający osiemnaście 3-krotek:
(MYSZ , 2 , BIAŁY )
(MYSZ , 2 , BRĄZOWY)
...
...
(ŻYRAFA , 400 , BIAŁY )
(ŻYRAFA , 400 , BRĄZOWY)
Przykładem relacji niech będzie podzbiór krotek spełniających warunek "jest w naszym ogrodzie zoologicznym". Będą to:
(MYSZ , 2 , BIAŁY )
(KOGUT , 40 , BIAŁY )
(KOGUT , 40 , BRĄZOWY)
(ŻYRAFA , 400 , BRĄZOWY)
Nazwijmy te relacje ZWIERZĘTA. Schematem relacji jest zbiór atrybutów (nazw kolumn):
ZWIERZĘTA ( NAZWA , WYSOKOŚĆ , KOLOR )
Jesli do tego mamy relacje o schemacie:
KLASYFIKACJA ( NAZWA, GROMADA )
( ŻYRAFA, SSAK )
( KOGUT, PTAK )
( MYSZ, SSAK )
Możemy utworzyć złączenie z relacją ZWIERZETA względem atrybutu NAZWA. Wygląda to następująco:
(MYSZ, 2, BIAŁY, MYSZ, SSAK)
(KOGUT, 40, BIAŁY, KOGUT, PTAK)
(KOGUT, 40, BRĄZOWY, KOGUT, PTAK)
(ŻYRAFA, 400, BRĄZOWY, ŻYRAFA, SSAK)
Jeśli jest to złączenie naturalne, będzie ono wyglądać następująco:
(MYSZ, 2, BIAŁY, SSAK)
(KOGUT, 40, BIAŁY, PTAK)
(KOGUT, 40, BRĄZOWY, PTAK)
(ŻYRAFA, 400, BRĄZOWY, SSAK)
Podstawowe pojęcia dotyczące projektowania baz danych
Relacja uniwersalna
Jest to relacja utworzona z wszystkich atrybutów projektowanej bazy danych. Relacja taka jest punktem wyjścia do tworzenia projektu struktury bazy danych.
Zależności
Mówimy, że atrybuty Y1, Y2, Y3 ... sa zależne od atrybutów X1, X2, X3, ...jeśli na podstawie znajomości wartości odpowiadających atrybutom X1, X2, X3 ... możemy określić wartości odpowiadające atrybutom Y1, Y2, Y3 ... Jesli zależność jest jednoznaczna, to nazywamy ją zależnością funkcyjna.
Jesli przez X oznaczymy zbiór atrybutów {X1, X2, X3,..}, przez Y zbiór atrybutów {Y1, Y2, Y3,...}, to powyższa zależność można zapisać jako: X -> Y. Mówimy też, że X wyznacza funkcyjnie Y (Y wynika funkcyjnie z X). Dalej będzie mowa wy łącznie o zależnościach funkcyjnych.
Domkniecie zbioru zależności F
Jest to zbiór zależności F uzupełniony o wszystkie zależności wynikające z zależności danych w F (np. na zasadzie przechodniości). Zbiór ten oznaczamy przez F+.
Domkniecie zbioru atrybutów X względem zbioru zależności F
Jest to zbiór wszystkich atrybutów, które wynikają z atrybutów X na podstawie jakiejkolwiek zależności z F+.
Klucz do relacji
Jest to taki minimalny zbiór atrybutów, którego domknięciem względem zbioru wszystkich zależności jest zbiór wszystkich atrybutów (czyli wszystkie atrybuty sa zależne od atrybutów klucza w sposób pośredni, lub bezpośredni). Wynika stad, że na podstawie wartości atrybutów klucza można jednoznacznie wskazać odpowiadające tym wartościom krotki.
Rozkład schematu relacji
Rozkładem schematu relacji R(A1,A2, .. ,An) jest taki zbiór schematów relacji R1, R2, .. ,Rn, ze zbiór atrybutów R jest suma zbiorów atrybutów R1, R2, ...
Złączenie naturalne relacji
Złączenie relacji jest odwrotnością rozkładu. Złączenie relacji A i B względem określonych atrybutów złączeniowych (A1, ... , Ai) i (B1, ... , Bj) oraz wyrażenia logicznego L jest relacja o następujących własnościach:
-
schemat relacji jest suma schematów relacji A i B
-
łączone są te krotki relacji A i B, których wartości składowych dla atrybutów połączeniowych spełniają wyrażenie L.
Złączenie naturalne jest to złączenie takie, że atrybuty złączeniowe dla obu relacji identyfikowane poprzez jednakowe nazwy, a warunek L jest koniunkcja warunków równości. W przypadku złączenia naturalnego do schematu relacji wynikowej atrybuty złączeniowe wchodzą jednokrotnie (przed złączeniem występowały dwukrotnie - w każdej z łączonych relacji).
Odwracalność
Rozkład schematu relacji R nazywamy odwracalnym, gdy R może być wyznaczone jako złączenie naturalne swoich rzutów na R1, R2, ..Rn. Odwracalność pozwala więc odtworzyć dowolna relacje z jej rzutów.
Zachowanie zależności
Rozkład zachowuje zależności F, gdy F jest równoważny zbiorowi tych zależności X->Y spośród F+, dla których suma X+Y zawarta jest w jednej spośród relacji R1, R2,.., Rn, na które rozłożono relacje R. Zachowanie zależności pozwala uniknąć potrzeby wykonywania złączeń w celu sprawdzenia zachowania więzów łączących atrybuty. Dla przytoczonego wcześniej przykładu o dostawcach przyjmijmy zależność:
{ NUM_DOST, TOWAR } -> { CENA }
Jesli numer dostawcy i identyfikator towaru będziemy pamiętać w innej relacji niż cenę, to dla sprawdzenia poprawności pamiętanych danych musimy dokonać ich połączenia.
Trzecia postać normalna
Rozkład jest w trzeciej postaci normalnej, jeżeli zawsze, gdy w R zachodzi X->A, oraz A nie należy do X, to X zawiera klucz do relacji R, lub też A jest atrybutem, który należy do każdego klucza tej relacji (tzn. jest jej atrybutem głównym). Taki rozkład pozwala uniknąć wszystkich nieprawidłowości, o których wspomniano wcześniej. Zainteresowanych dowodem tego stwierdzenia odsyłamy do literatury wymienionej na końcu opracowania, w szczególności do książki Ullmana.
Z powyższych uwag wynika, iż pożądane jest, aby rozkład schematu relacji uniwersalnej spełniał następujące warunki:
-
powinien on być w trzeciej postaci normalnej;
-
powinien zachowywać zależności;
-
powinien być odwracalny.
Projekt struktury logicznej bazy danych
Proces projektowania struktury bazy danych, zgodny z propozycją Ullmana obejmuje następujące czynności:
-
Spisanie wszystkich atrybutów mających wystąpić w bazie danych.
-
Relacje utworzona ze wszystkich atrybutów projektowanej bazy danych nazywamy relacją uniwersalną. Relacja taka jest punktem wyjścia do tworzenia projektu. Atrybuty tworzy się na podstawie własności obiektów (z analizy obiektowej), nie mających swojej wewnętrznej struktury.
-
Spisanie wszystkich zależności funkcyjnych między atrybutami.
-
Zależności między atrybutami najczęściej są związane z występowaniem odpowiadających im własności w ramach jednego obiektu nadrzędnego.
-
Dokonanie za rozkładu schematu relacji uniwersalnej do trzeciej postaci normalnej.
-
Nadanie poszczególnym relacjom nazw i wygenerowanie bazy danych z tabelami odpowiadającymi poszczególnym relacjom.
Literatura:
-
D.C. Tsichritzis, F.H. Lochowsky "Modele danych", W-wa 1990
-
Jeffrey D. Ullman “Systemy baz danych” WNT W-wa 1988
Wybrane publikacje w internecie na ten sam temat: